関連記事
部分的最小二乗回帰(PLS)を用いたぶどうの糖度算出に関するデモはこちら
03-3258-1238
お問い合わせ非破壊で糖度や水分量、タンパク質量といった定量値を予測する手法として、スペクトル解析があります。
その際、複雑で膨大なスペクトルデータからこれらの数値を正確に導き出すために、部分的最小二乗回帰(PLS:Partial Least Squares)が広く用いられています。
本記事では、PLSの基本的な仕組みやモデルの作成方法を、実例を交えながらわかりやすく解説します。
”果物の糖度”、”医薬品中の有効成分”、”水分割合”など、連続的な数値を求めたい場面では、単なる「ある/なし」の分類ではなく、「定量値の予測」が必要になります。
例えば、”果物などに光を当てて得られる近赤外スペクトルデータを解析すると、糖度などの成分量を非破壊で予測することができます。
この解析で使用されるスペクトルデータは、波長毎の輝度値のデータです。
波長400〜2500nmの範囲を1nm刻みで測定すれば、1画素あたり2100個の変数で構成されるため、データは非常に高次元かつ複雑であり、多くの変数が相互に似た情報を含むため、簡単には定量値の予測ができません。
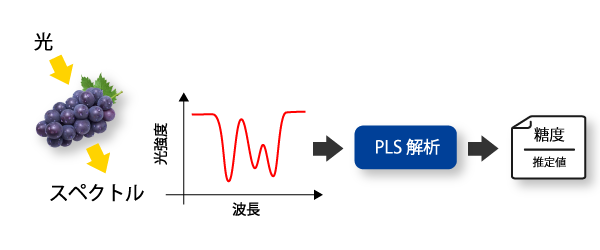
そこで活躍するのが、多変量解析手法のひとつである「部分的最小二乗回帰(PLS)」です。
PLSは、”スペクトル情報”と”予測したい数値(目的変数)”の関係性に注目して回帰モデルを構築する手法で、スペクトル解析における「定量値の予測」に広く利用されています。
PLSを用いたスペクトル解析は、さまざまな分野で定量値の高速かつ非破壊な予測手法として活用されています。
たとえば、果物の糖度や酸度、穀物中のたんぱく質量、医薬品に含まれる有効成分濃度の推定、茶葉の水分量の評価など、様々な製品の品質管理に応用が可能です。

ここでは、ぶどうの糖度の測定事例について紹介します。
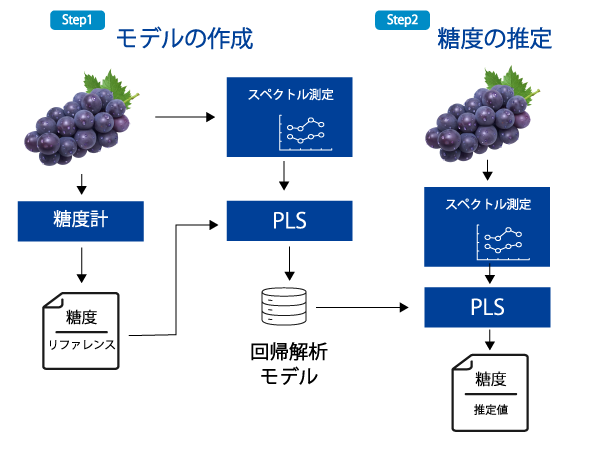
スペクトルからぶどうの糖度を推定するためには、モデルを作成する必要があります。
まずは、ぶどうに光を当ててスペクトルを取得するとともに、その果物の糖度を計測したデータを用意します。そして、PLSを用いて「この波長の組み合わせが糖度と強く関係がある」という回帰解析のモデルを作成します。
そして、この作成したモデルを使用して、ぶどうのスペクトルから糖度を推定します。

PLSと似た多変量解析手法に主成分分析(PCA)があります。

PCAは、スペクトル情報を「要約変数(主成分)」に圧縮することが可能で”データの特徴を知るための手法”なので、「分類」が得意です。
一方で、PLSは、スペクトル情報から、糖度、水分量、タンパク質量がどれくらい含まれるかを予測」に特化した手法で、「定量化」が得意です。
この違いは、解析の手法にも現れます。PCAは、説明変数であるスペクトルだけを見て次元を圧縮する手法で、”スペクトルの変化量が大きい部分”が抽出されます。一方、PLSは説明変数(スペクトル)と目的変数(糖度など)の関係に注目して次元を圧縮する手法で、”定量値”の予測にとって意味のある成分のみを抽出します。
PLSは、スペクトル波形が特徴的かよりも、目的変数(糖度など)と関係があるかという観点で情報(スペクトル)を圧縮するという点がポイントです。
ここからは、PLSによる定量化の原理について紹介していきます。
スペクトル解析による定量化では、波長ごとの輝度値という大量のデータ(説明変数:X)から、糖度や成分濃度などの定量値(目的変数:Y)を予測するモデルを作ります。

先にも述べたように、スペクトルデータの”膨大なデータ量”と、”多重共線性(互いに似た情報を含んでいる特性)”という特徴から、通常の回帰解析でモデルを作成することは容易ではありません。
そのため、PLSは、次元圧縮を行って情報を整理しながら回帰モデルを作ります。
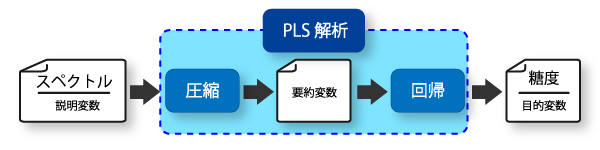
PLS(部分的最小二乗回帰)は、”説明変数”であるスペクトルデータの次元を圧縮した”要約変数”を持ちいて回帰を行うことで糖度などの定量値である”目的変数”を予測するモデルを作成します。
この手法のメリットを3つ紹介します。
次元を圧縮せずに全ての波長データを全て使用すると、目的変数(糖度)と相関のない波長も使用するため、その波長に含まれる測定誤差などのノイズがモデルに入ってしまいます。
PLSは、目的変数(糖度)との関係性が強い部分だけを抽出して使うので、ノイズの影響を低く抑えることが可能です。
通常の回帰分析(重回帰など)は「変数の数 < サンプル数」でないと予測精度が大きく劣化してしまいます。
特に、変数の数の多いスペクトルデータでは、サンプルの数を確保できないことが懸念されます。
PLSは、変数を圧縮して”目的変数”と強く関係のある成分を限定するので、サンプルが少なくても問題なく回帰モデルを作成することが可能です。
スペクトルデータでは、波長の間隔を狭くすればするほど、隣り合った波長が非常に似た動きをします。
これにより変数同士の情報が冗長になり、回帰解析では係数が不安定になる原因となります。
PLSは、次元を圧縮して共通の情報を持っている変数をまとめて圧縮するので、冗長性を取り除いた状態で回帰解析が可能です。
PLS(部分的最小二乗回帰)で使用する次元圧縮は、目的変数:X(スペクトル)と説明変数:Y(定量値)という両者の“共分散”が最大になるような新しい成分を抽出することで、定量値の予測にとって意味のある情報だけを残してデータを圧縮します。
共分散は、2つのデータがどれだけ連動して変化するかを表すもので、共分散が大きいほど、Xが増えるとYも増えるというように、2つのデータが同じ方向にうごく傾向が強いことを示します。
PLSが「XとYの共分散が大きい方向」になる成分を抽出するということは、X(スペクトル)の変動のうち、Y(定量値)の変動と強く関係している情報を優先的に取り出すことを意味します。これにより、Yを最もよく予測できる情報をXの中から抽出し、同時に、Yの予測に寄与しないノイズや不要な変動を取り除く効果があります。
その結果、PLSで得られる成分は、少ない次元数でも高い予測精度を維持できる特徴を持ち、特に多変量かつ高次元なスペクトルデータのモデリングにおいて非常に有効です。
PLSでは、目的変数(X)を圧縮して作成した要約変数(T)と目的変数(Y)の間にある“数値的な関係性”を数式(モデル)で表現します。
この数式が一度作られれば、新しいXの値(スペクトル)から、対応するYの数値(定量値)を計算できるようになります。
なぜこのようなことができるかというと、例えば「波長700nmの反射率が高いと、水分量が多い」というような連続した量同士の関係に、一定の傾向があるためです。
回帰分析ではこの関係性を学習し、数式で表します。
$$ Y = a_1 X_1 + a_2 X_2 + \cdots + a_n X_n + b $$
この数式のa1,a2,an,bがモデルの値であり、学習用のデータセットに対して、誤差が最も小さくなるようにこれらの値を決めます。
PLSでは次元を圧縮した後に回帰を行うことがキーポイントであることを述べてきました。
ここから、PLSモデルの作成について紹介していきます。
まずは、全体的な流れを説明します。
PLSのモデルを作成する際には、オーバーフィティングを避けるために、データセットを学習用と検証用に分けて、学習用のデータを用いて作成したモデルを検証用のデータを用いて評価するフローが一般的です。
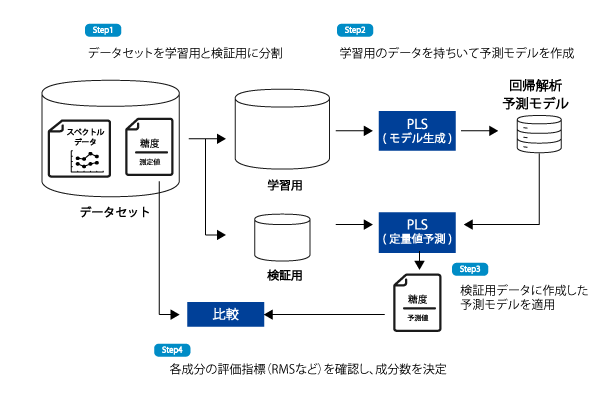
たとえば、サンプルが100個あるなら、80個のサンプルを予測モデルの学習用に、20個のサンプルを検証用に分けます。
この時、成分数を変更して、各成分数毎に予測モデルを作成します。
各成分数に対する予測結果と実際の値の誤差の二乗平均和である”RMS”などの指標を計算し、どれだけ正しく予測できたかを数値化する。
RMSを初めとした評価指標が最もよい成分数の予測モデルを評価して使用する。
ここでは、予測モデルの信頼性を正しく評価する必要があります。そこで、PLSの評価指標について、詳しく紹介していきます。
次に、前述のフローでどのようにモデルの作成や検証を行うかの手法についてです。
PLSのモデルを実際に構築するには、自身でプログラミングを行い実装する手法と、スペクトル解析ソフトを使用する手法があります。
Python、MATLABなどのプログラミング言語を用いて、PLS回帰モデルを自ら構築する方法です。
具体的には、Pythonのscikit-learnなどの既存のライブラリを活用することで、比較的容易に学習用データの読み込み、前処理、モデル学習、予測、評価といった一連の処理をスクリプト化して実行することができます。
自身でプログラムを作成するので、データの前処理手法の選択や、成分数の自動選択、交差検証の設定などをアプリケーションに応じてカスタマイズが可能ですが、プログラミングスキルが必要で、初心者にはややハードルが高い点がデメリットです。
スペクトル解析ソフトウェアを使用することで、マウス操作だけでPLSのモデルを構築することができます。
これらのソフトは、データのインポートから前処理、モデル構築、結果の可視化、評価指標の表示、レポート出力までを、わかりやすいGUIで簡単に実現できるよう設計されています。
例えば、Prediktera社の Breeze では、ユーザーがブロックをドラッグ&ドロップで並べるだけで、複雑な処理フローを直感的に作成できます。
さらに、スペクトル解析だけでなく、スペクトル画像からの対象抽出、測定結果の可視化、インライン機器への組み込みなど、前処理から実運用までを幅広くカバーしています。
「Breeze」は、ハイパースペクトルイメージング向けのスペクトル解析ソフトウェアです。
オブジェクト識別、画像セグメンテーション、スペクトル解析、機械学習モデルの適用などを、産業のインライン向けに簡単に組み込むための豊富な機能を搭載しています。
統計やプログラミングの知識がなくても扱える点は大きな強みで、現場の技術者や品質管理担当者にも広く利用されています。
特に、生産ラインなどの現場でモデルを迅速に作成・導入する必要がある場面に適しています。
ツールの購入には一定のコストがかかりますが、実際に自分でプログラムを書いて実装するための時間や人件費、開発リスクを考慮すると、結果的にトータルコストが安くなる可能性があります。
初期投資をすることで、開発スピードと運用効率を大幅に高められるのも、専用ソフトを利用する大きなメリットです。
自身でプログラミングを行い実装するか、スペクトル解析ソフトを使用するか、それぞれにメリット・デメリットがあるためアプリケーションや開発フェーズで、自身に合った方法を選択することが重要です。
モデルの作成に関する最後の項目として、考慮すべき点を2点紹介します。
PLSの制度にとって特に重要なのが「何個の成分を使用するか」です。
成分が少なすぎると必要な情報が欠落してしまい、成分数が多くなると過学習になってしまうため、どちらにしても精度が下がってしまいます。
”最適な成分数”を求めるためには、成分数を変更したモデルを作成して、最も誤差が小さくなる成分数を見つける必要があります。
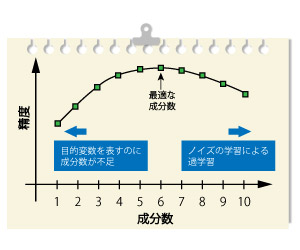
| 成分数 | 少ない | 多い |
|---|---|---|
| 問題点 | 目的変数との関係が十分に捉えられない | ノイズを学習し、過学習になる |
| 予測精度 | 低くなる | 低くなる |
PLSモデルにおいて、前処理も予測精度を大きく左右する重要な項目です。
測定環境やサンプル状態の違いによる外乱が精度に影響するため、微分処理、スケーリングなどを適切に使用してできる限りノイズを低く抑える必要があります。
また、全波長を使うのではなく、原理的に目的変数と強い関係のある波長帯のみを選択することも、精度及び処理時間の観点から重要です。
モデルを作成した後は、適切な指標を用いて性能を評価し、その結果に基づいて最適なモデルを選択する必要があります。
PLSで作成した予測モデルの評価には、二乗平均平方根誤差(RMS)、決定係数(R2)、予測決定係数(Q2)がよく用いられます。
それぞれの評価指標は、モデルがどれだけ正確に目的変数(Y)を予測できているかを数値的に示すものです。
RMS(Root Mean Square)は、予測値と実測値の誤差の大きさを表す指標です。
$$ \mathrm{RMS} = \sqrt{ \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 } $$
yi :実測値
ŷi:予測値
この指標が、誤差の評価値として様々な場所で用いられる理由は以下の3点にあります。
誤差をそのまま平均すると、正と負で打ち消し合ってしまいます。二乗することで、すべての誤差を正の値として扱います。
誤差を二乗することで、値が大きい誤差ほど大きく反映され、外れ値の影響を考慮することができます。
二乗した値の平方根を取ることで、元のデータと同じスケールになるため、誤差の大きさを直感的に把握できます。
これらの理由より、RMSはPLSの予測精度を総合的かつ直感的に評価するのに適した指標といえます。
RMSが小さいほど、モデルの予測精度が高いことを意味するので、RMSが小さいモデルを選択します。
R²は、モデルが目的変数(Y)の変動をどれだけ説明できているかを表す指標です。
$$ R^2 = 1 - \frac{ \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 }{ \sum_{i=1}^{n} (y_i - \bar{y})^2 } $$
yi :実測値
ŷi:予測値
ȳ :目的変数の平均値
この数式の分母 ∑(yi − ȳ)2 は、全体のばらつき(分散)を表し、分子 ∑(yi − ŷi)2 は、予測誤差の合計(残差平方和)を表します。
よって、この数式全体は、「予測誤差が全体のばらつきの中でどれだけの割合を占めているか」を計算しており、値の範囲は0から1で、1に近いほどモデルの説明力が高いことがわかります。
たとえば、R²が0.90であれば、「目的変数の90%はモデルによって説明されている」と解釈できます。
Q²は、交差検証を通じて得られる予測決定係数であり、R²と似た概念ながら、より汎化性能(未知データに対する予測力)に焦点を当てた指標です。
$$ Q^2 = 1 - \frac{ \sum_{i=1}^{n} (y_i - \hat{y}_{i,\text{eval}})^2 }{ \sum_{i=1}^{n} (y_i - \bar{y})^2 } $$
\( y_i \):測定値
\( \hat{y}_{i,\text{eval}} \):評価データに対するモデルの推定値
\( \bar{y} \):測定値の平均
PLSモデルの評価では、モデルの過学習を防ぎつつ、信頼性の高い予測モデルを構築する必要があります。
モデル作成時のデータに対する指標であるR²だけではなく、未知のデータに対する予測性能を示すQ²で客観的にモデルの精度を判断することも重要です。
Q²が高いほど、モデルが新しいデータに対しても正確な予測を行えることを示します。
部分的最小二乗回帰(PLS)が、高次元なスペクトルデータから定量的な情報を抽出するための有効な解析手法であることを解説しました。
目的変数と密接に関係するスペクトル情報に基づいて次元を圧縮し、高精度な予測モデルを構築できる点が大きな特徴です。
また、多重共線性への強さや、サンプル数が少ない場合でも適用できる柔軟性など、多くの利点があります。
モデル構築時には、成分数の最適化や、RMSE・R²・Q²といった指標による予測精度の評価を通じて、信頼性の高いモデルを作成することが重要です。







