
[2.1]スペクトル解析の前処理 (②ノイズ低減と特徴強調)
基礎編:スムージングと微分
スペクトルデータには、測定によるノイズが含まれています。
これらのノイズは、測定環境や装置(カメラ)の特性、試料の不均一性など、さまざまな要因によって発生します。
測定時にこれらの影響を完全に取り除くことは難しいため、取得したデータからノイズを低減し、特徴を強調することが、解析の精度を高める上で非常に重要です。
本記事では、前章で解説した「スペクトル解析の前処理(①輝度値補正)」に続き、ノイズ低減や特徴強調に焦点を当て、波形整形の手法について解説します。
具体的には、スムージング、1次・2次微分、およびSavitzky-Golayフィルタの目的や利点、そしてPythonでの実装方法について詳しく説明していきます。
1. 波形整形に使用するスムージング、微分、Savitzky-Golay
「測定データに含まれるノイズの低減」や「測定データの特徴の強調」のために、スムージング、1次微分、2次微分、およびSavitzky-Golayフィルタといった波形整形手法が広く使用されます。
これらの手法はそれぞれ異なる目的を持っているため、目的を理解した上で、どの手法を選ぶべきかを判断し、正しく使用することで、正しく目的を果たすことができます。
そして、後続のスペクトル解析(例えば、統計解析、機械学習)において、信頼性の高い結果を得ることにつながります。
以下の表で、スムージング、1次・2次微分、およびSavitzky-Golayフィルタの目的、利点、使用例を紹介します。
| 特徴 | スムージング | 微分(1次・2次) | Savitzky-Golayフィルタ |
|---|---|---|---|
| 目的 | ノイズの低減 (データの平滑化) |
ピークの強調 | ノイズ低減とピーク強調の同時実行 |
| 利点 | 高周波ノイズを除去し、データの変動を滑らかにすることができる | データの変化からピークを強調することができる | ピークや特徴点を保持しつつノイズ低減することができる |
| 使用例 | スペクトルがノイズの影響でギザギザしている場合や、線幅が太く見えてピークの判別が難しい場合に、波形を滑らかにしてデータの傾向を明確にする。 | 1次微分:スペクトルがどこで変化しているかを分かりやすくする。 2次微分:ピークの位置をはっきりさせる。 |
スペクトルのピーク位置や形をできるだけ保ちながら、ノイズを低減して見やすくする |
スペクトル解析の波形整形には、一般的にはノイズ低減と特徴強調の両方を併せ持つSavitzky-Golayフィルタが使用されることが多いですが、このフィルタを使いこなすには、ベースとなるスムージングと微分の内容も理解しておくことが重要です。
ここからは、ノイズ低減と特徴強調の「基礎編」として、スムージングと微分の内容とそのプログラムについて詳しく解説していきます。
2. スムージングによるノイズ低減
本章では、データの変動を滑らかにして、ノイズを低減する「スムージング」の概念から実際のPythonコードを用いた実装例まで、順を追って解説していきます。
2.1 スムージングの概念
スムージングには様々な方法が存在しますが、一般的なのは、移動平均法、ガウスフィルタ、多項式フィッティングなどです。
まずは、この違いについて紹介します。
| 手法 | 移動平均法 | ガウスフィルタ | 多項式フィッティング |
|---|---|---|---|
| 概要 | 窓内の値を単純平均する線形フィルタ。 実装が簡単。計算も軽い。 |
ガウス分布の重みで畳み込みする平滑化。 補正後の波形が自然ななめらかさとなる。 |
窓内データに低次多項式を最小二乗で当てはめて、中央点を評価することで平滑化。 |
| 用途 | 簡易的に、全体をなめらかにしたい時。 | 形をできるだけ自然に保ちつつ、ノイズを抑えたい時。 | ピーク形状を保ちながらノイズ低減したい時 |
| 利点 | 単純、高速。効果が直感的。 | 波打ちが出にくい。移動平均より形状が保持される。 | ピークトップを保ちやすく、局所トレンドを維持できる。 |
| 気をつける点 | ピーク頂点が平らになりやすい。端点で歪みやすい。 | ピークがやや広がる。 パラメータ(σ)の選定が重要。 |
窓幅と次数を選択する必要がある。 次数を上げすぎるとオーバーフィッティングになる。 |
それぞれの手法には利点がありますが、スペクトル解析におけるスムージングでは、単にノイズを低減するだけでなく、ピーク位置や局所的な変動といった重要な特徴を保持することが求められます。
そのような条件を満たす手法としては、データを滑らかにしつつ形状情報を保つことができる「多項式フィッティング」がおすすめです。
おすすめの多項式フィッティングについて、掘り下げて解説していきます。
2.2 スムージングの計算式 (多項式フィッティング)
多項式フィッティングを用いたスムージングの計算手順は以下の3Stepです。
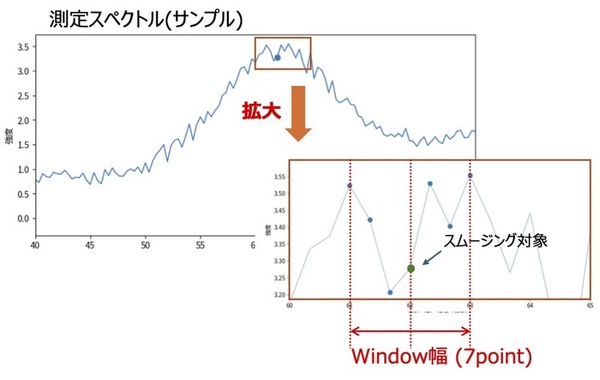
①ウィンドウ幅の選択
データの各点(スムージングポイント)に対して、その点を中心とするウィンドウ幅を選択します。
各点のスムージング後の値は、このウィンドウ内のデータを対象にして求めます。
(ウィンドウはスムージング対象のポイントを中心として左右に同じ個数を取るので、ウィンドウ幅は一般的に奇数になります。)
例
以下は、ウィンドウ幅を7pointにした場合の例です。
②多項式によるフィッティング
各データ点について、あらかじめ取得したウィンドウ内のデータを用いて多項式回帰を行います。一般的には、2次または3次の多項式が用いられます。
例えば2次多項式を用いる場合、最小二乗法により次式の形でデータをフィッティングします。
P(x) = a2x2 + a1x + a0
このようにして求めた2次多項式をウィンドウの中心点で評価し、その値を解析対象データのスムージング後の値とします。
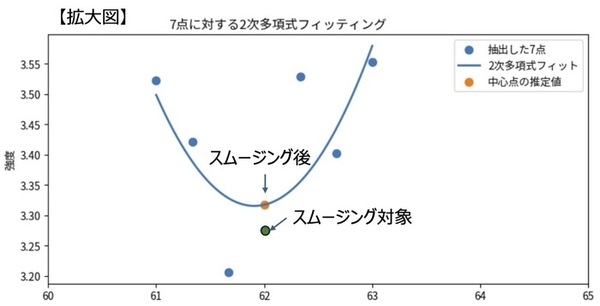
例
以下に、①で選択した7点のデータを抽出し、2次多項式でフィッティングした例を示します。
図中の曲線がフィッティングされた2次多項式であり、この曲線上におけるスムージング対象のX座標の値が、スムージング後のデータ値となります。
③多項式によるフィッティングをスペクトル全体に適用
前節で説明した多項式フィッティングを、スペクトル中の各データ点に対して順次適用します。
この操作をスペクトルの全領域にわたって繰り返すことで、各点のスムージング後の値が求められ、ノイズが低減されつつもピーク形状や局所的な変動が保持されたスペクトルが得られます。
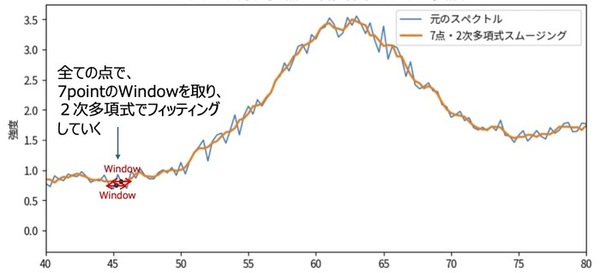
例
以下に、これまで例として挙げてきたWindowを7点、2次多項式でスムージングをすべてのポイントで実施した例を紹介します。
スムージング前後の波形を比べると、スムージング後の波形はギザギザがなくなり滑らかになっていることがわかります。
ウィンドウ幅や多項式の次数は、ノイズ低減効果と形状保持のバランスを考慮して適切に選択する必要があります。
2.3 Pythonでのスムージング コマンド
Pythonで多項式フィッティングを行う方法はいくつかありますが、ここでは「NumPy」のpolyfitとpolyvalを使用した方法を紹介します。
np.polyfit 関数とは
入力データに対して多項式フィッティングを行い、与えられたデータに最小二乗法を使って多項式をフィッティングし、その多項式の係数(p)を返す関数です。
コマンド使用方法
p = np.polyfit(x, window_data, poly_order)
- x:データの x 軸の値(0 から始まる連番)
- window_data:ウィンドウ内に含まれるデータの y 軸の値
- poly_order:多項式の次数
np.polyval関数
np.polyfit 関数でフィッティングした多項式(p)を使って、元のデータに対するスムージング後データを出力します。
コマンド使用方法
smoothed_data[i] = np.polyval(p, half_window)
- p : フィッティングによって求められた多項式の係数。
- half_window:ウィンドウの中心点から考慮する距離
2.4 スムージングのPythonでの実装例
スペクトルのデータ、ウィンドウサイズ、多項式の次元を入力として、np.polyfitでスムージングの係数を求め、np.polyvalを用いてスムージングを行い、スムージング後のスペクトルデータを出力する関数”smoothing_spectral”を作成してみます。
import numpy as np # NumPyライブラリの読み込み
def smoothing_spectral(data, window_size, poly_order):
smoothed_data = np.copy(data) # 出力先の配列を作成し、元データをコピー
half_window = window_size // 2 # ウィンドウ幅の半分を計算し、”中心から左右に何点見るか”を算出
for i in range(len(data)): # 各データ点 について繰り返し処理を設定
# 各データ点における、Windowの開始・終了ポイントの設定(配列端を越えないように考慮)
start = max(i - half_window, 0)
end = min(i + half_window + 1, len(data))
window_data = data[start:end]. #各データ点におけるWindow内のデータを抽出
x = np.arange(len(window_data)) #window_dataに対応するx値([0,1,2,3,....]という配列)を設定する。
p = np.polyfit(x, window_data, poly_order) # poly_order で多項式パラメータpを算出。
smoothed_data[i] = np.polyval(p, half_window) # 算出した多項式 pをスペクトルデータに適用。
return smoothed_data # 平滑化後の配列を返す。
作成した関数の使い方
作成した関数 smoothing_spectral は、1 次元のスペクトル(data)などに対して、window_size内で多項式フィット(次元: poly_order)を行い、スムージング処理を行うことが可能です。
基本的な呼び出しは、以下のように、引数で、スペクトルデータ(data)、Windowのサイズ(window_size)、多項式の次元(poly_order)を指定します。
smoothed_data = smoothing_spectral(data, window_size=7, poly_order=2)このようにして得られた、smoothing_spectralをplt.plotで表示すると、スムージング後のスペクトルを確認することができます。
3. 1次微分・2次微分による特徴抽出
本章では、ピークを強調する「微分」の概念から実際のPythonコードを用いた実装例まで、順を追って解説していきます。
3.1 1次微分・2次微分の概念
1次微分と2次微分は、スペクトルデータの吸収ピーク検出やトレンドの変化の特徴抽出に非常に役立ちます。
まずは1次微分と2次微分の違いを紹介します。
1次微分の概念
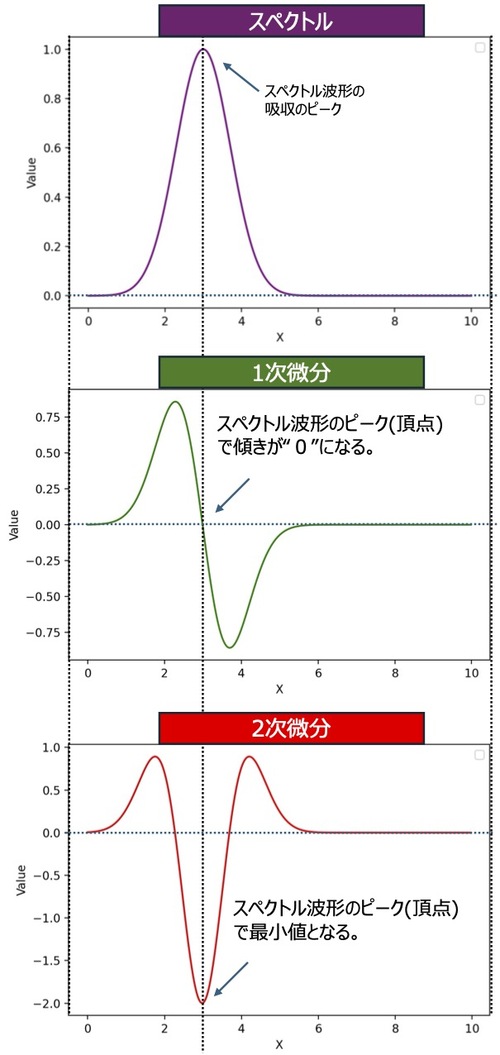
1次微分は、「データの傾き(変化率)」を示します。
そのため、スペクトルデータのピークの頂点において、1次微分の傾きが”0”になります。
これによりスペクトルの変化点を見つけることができます。
2次微分の概念
1次微分が「データの傾き」や変化率を示すのに対し、2次微分はさらにその「傾き」となるので、「変化率」を示します。
スペクトル解析において特に重要となるのは、吸収ピーク(山)や谷の頂点です。
これらの頂点では、1次微分の傾きがゼロになり、傾きの方向がプラスからマイナスに切り替わります。この切り替わるポイントで、2次微分が極小値を取るため、ピークの位置を見つけることができます。
1次微分、2次微分の例(単一ピーク)
以下は、単一のピークがあるスペクトルに対して、1次微分と、2次微分を行った例です。
2次微分を利用することで、1次微分よりもピークの位置を明確に特定できていることがわかります。
3.2 1次微分・2次微分によるピーク分離の詳細
次に、より具体的で実践的な例として、微分処理を用いたピークの分離について紹介します。
実際のスペクトルでは、吸収ピーク同士が近接して存在することが多く、強度の低いピークが、強度の高いピークに隠れてしまう場合があります。
例えば、検出対象とするプラスチックの吸収ピークが、水の強い吸収ピークに重なり、スペクトルからはプラスティックの判別が困難になるといった状況が挙げられます。
1次微分、2次微分の例(複数ピーク)
以下は、複数のピークが重なっているスペクトルに対して1次微分と、2次微分を行った例です。
特に、大きいピークに小さいピークが隠れてしまうと、目視でスペクトルから小さいピークを見つけることは困難なことがわかります。
このようなスペクトルでも、2次微分処理を行うことで、ピーク位置に対応する特徴的な変化が強調され、2つのピークが分離して検出できます。
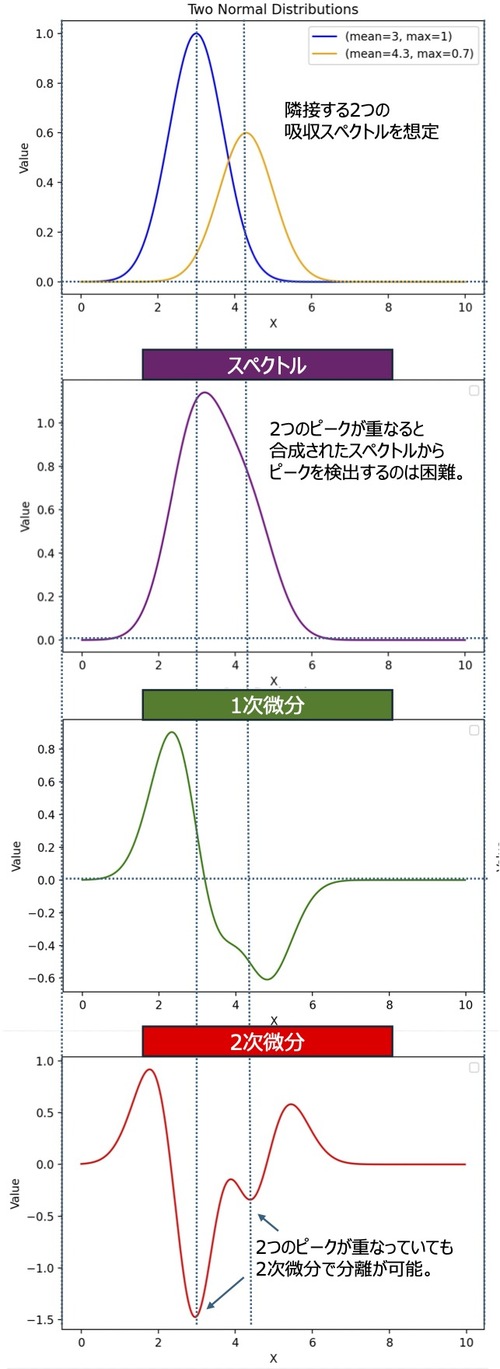
2次微分スペクトルでは、元のスペクトル中のピーク位置が「極値」として現れるため、その後の解析で使いやすくなるといのが大きな利点です。
3.3 Pythonでの1次微分・2次微分 コマンド
1次微分と2次微分もスムージング同様Numpyのライブラリを使用して実現することが可能です。
以下に、微分値を計算するための簡単なコードを紹介します。
Pythonでの1次微分コマンド
1次微分の数式
前提となる1次微分の数式ですが、スペクトルデータは測定点が有限個で連続関数ではないため、厳密な意味での微分を計算することはできません。
しかし、波長間隔 Δx が十分に小さく、スペクトルが滑らかに変化している場合、隣接点の差分 Δy / Δx は「区間の平均的な傾き」を表すため、1次微分の近似値として扱うことができます。
1次微分数式 = \(\frac{dy}{dx}\)
スペクトルデータは、各波長に対する輝度(強度)で構成されているため、Δyは隣接する波長点間における輝度(強度)の変化量、Δx は隣接する波長の差です。
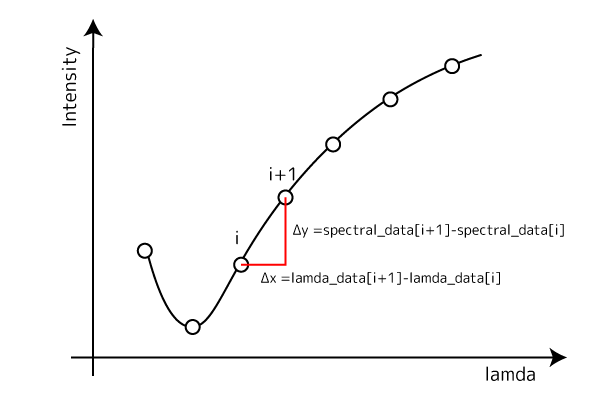
サンプルコマンド
スペクトルデータの配列(spectral_data)の微分値 Δy / Δx をPythonで計算するには、NumPyのnp.diffコマンドが有効です。
np.diffは、NumPy配列の隣り合う要素同士の差を計算する関数で、入力配列(spectral_data)に対して spectral_data[i+1] - spectral_data[i] を順に求め、その結果を新しい配列として返します。
スペクトルデータの配列を spectral_data、波長配列を lamda_data としたとき、次のコマンドで1次微分(前進差分)の配列を求めることができます。
np.diff(spectral_data) / np.diff(lamda_data)Pythonでの2次微分コマンド
2次微分の数式
2次微分は、1次微分が表す「傾きの変化」をさらに波長方向で評価した量であり、スペクトル形状のピークを捉えるために用いられます。
1次微分と同様に波長間隔 Δx が十分に小さいと仮定すれば、1次微分をさらに微分することで2次微分を近似することができます。
2次微分数式 = \(\frac{d^2 y}{dx^2} = \frac{d}{dx}\!\left(\frac{dy}{dx}\right)\)
サンプルコマンド
スペクトルデータの配列を spectral_data、波長配列を lambda_data とした場合、
2次微分の近似値は次のように計算できます。
・1次微分をさらに微分する方法
これは、「2次微分=1次微分をさらに微分する」という計算で、不等間隔の波長データにも対応しやすいという特徴があります。
・2次差分を直接用いる方法
分子にスペクトルデータに対して2回差分を取った値np.diff(spectral_data, n=2) を
分母に隣接する波長差 Δx を2乗した値 (np.diff(lambda_data)**2) を取ることで、2次微分を1つの式で計算することができます。
d1 = np.diff(spectral_data) / np.diff(lambda_data)
np.diff(d1) / np.diff(lambda)このような計算により得られる2次微分の配列は、スペクトル形状の曲率を表し、ピーク検出やノイズ除去前の特徴抽出などに活用されます。
3.4 1次微分・2次微分のプログラム実装例
以下に、1次微分と2次微分を計算し、それぞれの結果をプロットする実例を示します。
以下のサンプルスクリプトは、以下の手順で処理を実行します。
- 複数のガウシアンピークを持つスペクトルを疑似データとして作成
- 1次微分と2次微分を計算
- スペクトル(強度)を第1軸(左軸)、1次微分・2次微分を第2軸(右軸)としたグラフを表示
import numpy as np
import matplotlib.pyplot as plt
# 波長軸サンプル作成(nm)
lambda_data = np.linspace(400, 700, 300)
# 分光スペクトルの疑似データ作成
spectral_data = (
np.exp(-((lambda_data - 450) / 15)**2) +
np.exp(-((lambda_data - 550) / 25)**2) +
np.exp(-((lambda_data - 650) / 20)**2)
)
# 1次微分計算
d1 = np.diff(spectral_data) / np.diff(lambda_data)
# 2次微分計算
d2 = np.diff(d1) / np.diff(lambda_data[:-1])
# スペクトルデータのプロット
fig, ax1 = plt.subplots(figsize=(8, 6))
ax1.plot(lambda_data, spectral_data, label="Spectrum")
ax1.set_xlabel("Wavelength (nm)")
ax1.set_ylabel("Intensity")
ax1.grid(True)
ax2 = ax1.twinx()
ax2.plot(lambda_data[:-1], d1, linestyle="--", label="1st derivative")
ax2.plot(lambda_data[:-2], d2, linestyle=":", label="2nd derivative")
ax2.set_ylabel("Derivative value")
# 凡例
lines1, labels1 = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax1.legend(lines1 + lines2, labels1 + labels2, loc="upper right")
plt.show()
サンプルスクリプト実行結果
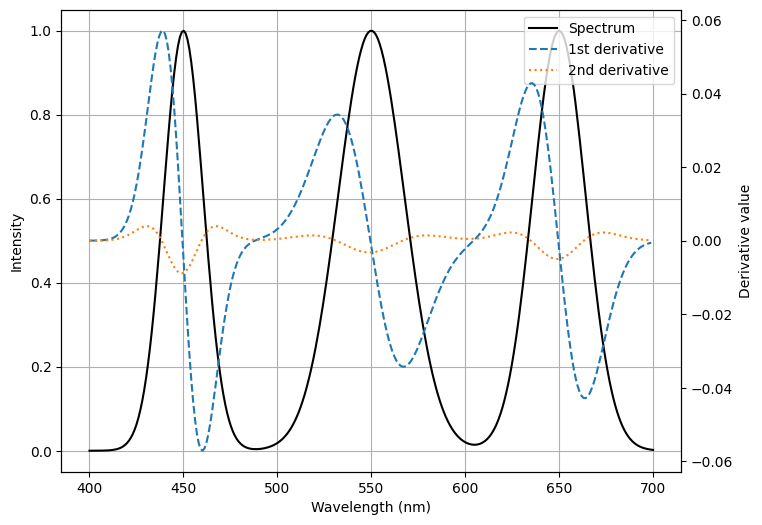
1次微分はピークの立ち上がりで正、立ち下がりで負となり、ピーク頂点付近で0に近づいています。
また、2次微分はピーク中心付近で負の極小となるため、ピーク位置や形状の評価に利用できます。
4. まとめ
本記事では、分光スペクトル解析における「ノイズ低減」と「特徴強調」のための波形整形手法について解説しました。
スムージングによるノイズ低減については、移動平均法・ガウスフィルタ・多項式フィッティングの特徴を整理し、特にピーク形状を保ちやすい多項式フィッティングの考え方とPythonでの実装例を紹介しました。
次に、1次微分・2次微分による特徴抽出について、ピーク分離への有効性を説明し、同じくPythonでの実装例を紹介しまいた。
これらのスムージングや微分処理は、後続の統計解析や機械学習を含むスペクトル解析の精度向上に直結する重要な前処理です。
また、Savitzky-Golayフィルタを理解・活用するための基礎にもなります。
目的やデータ特性に応じた適切な前処理手法としてご活用ください。
このカテゴリのコンテンツ






関連コンテンツ





ハイパースペクトルカメラコース
スペクトルカメラ知識コンテンツ
スペクトルカメラ技術基礎
スペクトル解析
スペクトルカメラ論文
スペクトルカメラの選び方
スペクトルカメラのデモ
スペクトルカメラアプリケーション
- ハイパースペクトルカメラで樹脂や金属の劣化を読み解く新技術
- SDGsと光学機器・センサー
- ハイパースペクトルカメラ事例集
- 見えない異物を検出
- 人手不足の現状と次世代の省人化技術、ハイパースペクトルカメラの可能性
- ハイパースペクトルカメラによるカーボンニュートラル実現に向けた技術革新の効率化
- ハイパースペクトルカメラで加速する脱プラスチック
- ハイパースペクトルカメラがもたらすDX
- 膜厚測定
- クロロフィル測定とは?
- 偽造防止印刷とは?
- 近赤外分光で繊維選別
- ハイパースペクトルカメラ事例|工業分野
- プラスチック資源循環促進法とは
- 近赤外分光でプラスティック選別
- 半導体・フィルムの膜厚測定
- マシンビジョンでの活用事例
- ハイパースペクトルカメラ事例|食品分野
- 食品産業業界の未来を考える
- 食品産業で活躍するIoTセンサー
- ハイパースペクトルカメラ事例|医療分野
- 医療分野での活用
- ハイパースペクトルカメラ事例|インフラ分野
- インフラ(コンクリート)の維持保全
- ハイパースペクトルカメラ事例|防衛・セキュリティー分野
- ハイパースペクトルカメラ事例|リモートセンシング
- ハイパースペクトルカメラ事例|農業分野