3Dカメラの場合は、光情報から「奥行き情報」を取得します。XYZの座標情報、つまり「深さ」の情報です。
このような深度データは、ポイントクラウドや点群データと呼ばれます。[1]
03-3258-1238
お問い合わせ2023.02.17 | 産業用ロボット, ばら積みピッキング
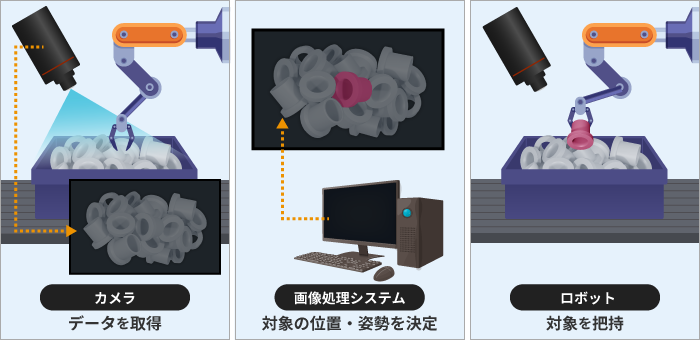
ロボットビジョンとは、ロボットの視覚機能です。
大まかには、シーンを知覚する「カメラ」と、カメラから得た情報を処理する「画像処理システム」、さらに画像処理システムから情報を受け取り、タスクを実行する「ロボット」によって構成されます。
特に産業用途の場合ですが、視覚機能(ロボットビジョン)は、必須ではありません。
そもそも「産業用ロボット」は「3軸以上かつプログラムが可能で産業自動化に用いられるロボット」と定義されます。
「産業用ロボット」の定義は、日本産業規格に示されています。以下はその要約です。
自動制御され、再プログラム可能で、多目的なマニピュレータであり、3軸以上でプログラム可能で、1か所に固定して又は移動機能をもって、産業自動化の用途に用いられるロボット。
定義を見ると、視覚機能がなくても産業用ロボットとして成立することが、わかります。
しかし、ロボットビジョンにはニーズがあります。
それは、産業用ロボットに、視覚機能(ロボットビジョン)を持たせることで、ピッキングなどのタスクを実行でき、ひいては省人化や生産性のアップに繋がるからです。
例えば、ばら積みピッキングなど、ロボットだけでは実行できない、あるいは実行が困難なタスクも、ロボットビジョンによって実行できます。
当ページでは、産業用ロボットを中心に「ロボットビジョンの理解に必要なポイント」を整理してまとめました。
特に、ロボットビジョンは「全体像」や、カメラ等がタスクの実行にどう貢献しているのかという「構成要素の役割(仕組み)」が理解しにくいポイントかと思いますので、具体例を挙げながら、わかりやすくお伝えしていきます。
また「なぜ視覚機能が必要なのか?」という疑問もあるかと思います。
その辺りは「導入のメリット」と併せてお伝えします。
まずは「ロボットビジョンの全体像」から、見ていきましょう。
ロボットビジョンは、ロボットの「視覚機能」を指します。
人間の視覚機能は「目で見て、脳で判断して、体を動かすこと」を指しますが、ロボットも同様で「カメラで見て、コンピューターで判断して、マニピュレーター(実機)を動かすこと」までを含みます。
つまり、カメラ単体では完結しません。
具体的には、例えばロボットビジョンを用いた場合、ばら積みピッキングは次のように実行されます。
情報を取得する

3Dカメラでばら積みされた全体を撮影し、シーンの3次元点群を取得する
認識

画像処理システムがばら積みのヤマの中から対象を認識し、把持点などを決定する(=位置・姿勢を決定する)
ロボットに出力する
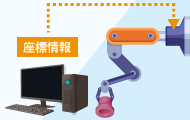
把持点と傾きの座標情報(XYZ, RPYの6座標)を、ロボットの座標系に変換して出力する
[1], [2]を参考に作成
カメラが認識した情報を処理して、ロボットが必要とする形で出力することで、ロボットは対象の位置に加え、把持点(掴む位置)などを認識でき、ピッキングなどのタスクを実行できます。
つまり、カメラから得た情報の処理や、その情報をロボットが必要とする形で出力するといった、ロボットの動作を含めた一連のプロセスがロボットビジョンです。
ここではロボットビジョンの仕組みとして、ロボットの視覚機能の構成要素と、それぞれの役割(機能)を見ていきます。
ロボットビジョンは、主に、シーンを知覚する「カメラ」と、カメラから取得した情報を適切な形で処理する「画像処理システム」、そしてタスクを実行する腕や手としての「ロボット」で構成されます。
それでは、それぞれの役割を見ていきましょう。
カメラは視覚機能における、目の役割を果たします。
目は「光を受け取る感覚器」です。カメラも光情報を受け取るセンサーとしての役割を果たします。
2Dカメラの場合、用途によっては、赤外線等、人間の目に見えない波長を使用するケースもあります。
3Dカメラは、主に撮影方式によって分類されます。(詳細:3Dカメラとは)
ロボットビジョンでは、ステレオ方式のカメラ(ステレオカメラ)が、よく用いられます。
ステレオ方式
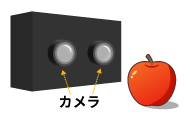
複数台カメラを使用し、三角測量によって奥行き情報を求める
ToF方式
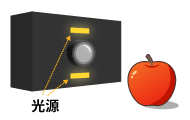
カメラと光源を組み合わせ、光の飛行時間から奥行き情報を求める
構造化照明

カメラとプロジェクターを組み合わせる
2Dカメラ(可視光)の場合は、色や明るさといった「光情報」を取得します。加えて、XYの座標情報も取得できます。
3Dカメラの場合は、光情報から「奥行き情報」を取得します。XYZの座標情報、つまり「深さ」の情報です。
このような深度データは、ポイントクラウドや点群データと呼ばれます。[1]
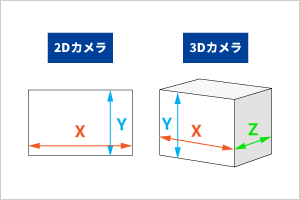
2Dカメラと3Dカメラ
画像処理システムは、ロボットビジョンにおける脳の役割を果たします。
例えば「事前に登録した対象の形状や大きさなどを記憶する」こともできますし、また「モデルと照らし合わせて対象を認識する」こともできます。
対象の認識は、カメラから受け取った情報を処理することで行います。
他にも、ロボットビジョンでは、主に画像認識、物体認識、環境地図作成が行われます。
| 説明 | 用途例 | |
|---|---|---|
| 画像認識 | 画像から特徴を抽出して、対象を識別する(パターン認識) | ワークの位置決め、不良品の検知 |
| 物体認識 | 機械学習やディープラーニングを用いて、画像や動画内の物体を識別する 対象の位置や姿勢を認識する[1] | 外観検査、ばら積みピッキング |
| 環境地図作成 | 無人搬送車(AGV)やドローンなどが環境地図を作成し、周辺の障害物などを認識する | 無人搬送(物流倉庫など) |
画像処理システムによって処理された情報は、ロボットに出力されます。
例えば、ばら積みピッキングの場合は、無作為に積まれたヤマから「対象」を見つける必要がありますが、この場合は「物体認識」によって、シーンの中から掴む対象の位置・姿勢を認識します。[1]
画像処理システムからの情報を元に、ロボットが動作します。
ピッキングの場合、アーム等で対象を把持(固定)して、決まった場所に移動させます。
ロボットビジョンは、主にカメラ、画像処理システム、ロボットの3つの要素で構成されています。
各構成要素は「情報の受け渡し」を行なっています。
カメラから画像処理システムへ、画像処理システムからロボットへと、情報を渡すことで、タスクを実行しています。
タスクの実行に必要な情報を、カメラが取得し、画像処理システムが情報を処理します。その処理情報を元に、ロボットがタスクを実行します。
産業用ロボットに、ロボットビジョンを導入するメリットとして挙げられるのは、主に次の3点です。
「ロボットに視覚機能を持たせると何ができるか?」を把握すると、これらのメリットを理解しやすくなります。そのため、逆に「視覚機能がない場合」を考えてみましょう。
視覚機能がない産業用ロボットは、あらかじめ決められた動きを精度よく高速に繰り返すことでタスクを実行します。[2]
作業の実行には、ティーチング(教示)が欠かせません。
教示は、労働安全衛生規則第36条(第31条)に正確に定義されています。主に、次のような内容です。
産業用ロボットの稼働範囲内において、マニピュレーターの「動作の順序」、「位置もしくは速度の設定」、「変更もしくは確認」を教示等という。
産業用ロボットには、位置や姿勢、関節を動かすタイミングなどを、細かく指示する必要があります。
ティーチングによって、最適な動きを事前に定義し、ロボットはその動きを再現し作業を行います。つまり、ロボットが作業するためには「作業対象が決まった位置・姿勢」にあることが前提になります。[2]
このため「作業対象を決まった位置・姿勢」に揃える段取りが必要になり、手間がかかります。
ティーチングの様子(イメージ図)
位置や姿勢だけでなく、サイズや形状が異なる対象には対応できないため「作業対象が毎回固定」である必要もあります。大雑把に言えば、部品Aをピックするようにティーチングを行った場合は、部品Bをピックできません。部品Bをピックするためには、再びティーチングが必要になります。
加えて、ティーチング自体も誰でも行えるものではなく、特別な技能が必要になります。さらに、実際のティーチングには時間がかかります。
「視覚機能がない場合」を考えると「なぜ視覚機能が必要なのか?」が理解しやすいと思います。
つまり、ロボットに視覚機能を持たせることで、これらの課題を解決できるからです。
ロボットビジョンなら、上述の問題を解決できます。
産業用ロボットに視覚機能を持たせることで、対象を認識できるようになります。
このため、作業対象が決まった位置・姿勢でなくとも、ばら積み・混載の場合でも、タスクを実行できます。
作業対象を決まった位置・姿勢に揃えるために、段取りを整えたり、専用の治具を用意したり、ラインを構築したりする必要がなくなり、コストの削減につながります。
またロボットも「決まった動作を繰り返す」わけではないため、そうした意味でのティーチングは不要になります。
ティーチング技術者の育成には時間がかかりますし、加えてティーチング技術者自体も不足しているため、ロボットビジョンの活用で「ロボットを導入したもののティーチングがうまくできず思ったように活用できない」という事態も防げます。
以下のようなお悩みがある場合、弊社(ケイエルブイ株式会社)が解決をお手伝いできる可能性があります。
こちらは画像解析・プログラミング不要で、ロボットと連携できる、3Dカメラシステム「RC_VISARD」です。
3Dカメラとして深度データを取得できるだけでなく、カメラそれ自体が、対象の位置・姿勢・サイズを自動で検出できます。

3D カメラシステム「RC_VISARD」
さらにカメラ側で(オンボードで)、「把持点の検出」や「ロボットの座標系への変換」も可能です。
「RC_VISARD」には、用途に応じたアプリケーションモジュールが用意されており、適したモジュールを選択することで、上述のような画像解析のタスクを実行できます。
このため、特に画像解析に課題を感じている方にお勧めです。
また、当製品を用いることで「画像処理プログラムの開発」が不要になります。そのため、価格や工数を抑えて、スムーズに導入できます。

画像解析・プログラミング不要で、ばら積みの対象を認識できます。
用途に合わせたアプリケーションモジュール(球体、多面体の最もフラットなポイントを算出できる「アイテム・ピック」など4種類)を選ぶことで、対象を認識し、ピッキングできます。
[1]橋本学「物体認識のための3次元特徴量の基礎と動向」(最終閲覧日:2022年2月17日)
[2]徐剛「ピッキングロボットのための3次元ビジョン」(最終閲覧日:2022年2月17日)

機械学習/ディープラーニングを活用したスペクトル解析

「プラスチックの選別」に革新!
近赤外分光がプラスチックのリサイクルに貢献

ハイパースペクトルカメラ導入の費用対効果は?

【第1回】光学機器商社がレタスで実験してみた!
種まき編









